MLflow Pluginの作り方
この記事はMLOps Advent Calender 2020の21日目の記事です.
日本でもMLflowの利用事例が増えてきていて特に実験管理に使われることが多いです. 特に2020年はMLflowを使った記事がいくつも公開されています.
- ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう-
- MLflowで実験管理入門
- 小さく始めて大きく育てるMLOps2020
- MLflow Tracking を用いた実験管理
MLflowは実験管理以外にもモデルの管理機能やモデルのサービング, 処理の実行機能があるのですがそれらはあまり使われていない印象です. モデルのサービングはTensorflowやPyTorchといった学習フレームワーク自身がサポートしはじめていていくつかMLOpsの事例を見てもそれらを使うケースが多いようです. 一方で今年のData + AI Summit Europe 2020ではMLflowのモデルサービングをプロダクション環境で使った発表もあり今後増えていくこともあるだろうと思っています.
メタデータ管理としてのMLflow
MLflowの実験管理はGoogleのMLOps: 機械学習における継続的デリバリーと自動化のパイプラインでいえばMLOps Level1のメタデータ管理の機能に相当します. メタデータ管理が記録するのはMLの再現性の担保やデバッグに活用される実行時の情報です.
大手クラウドプロバイダや海外のベンチャー企業が様々なMLOpsのためのサービスを提供していますが単一のマネージドサービスで全ての要件が賄えることは稀です. 実際に使ってみると足りない機能が次々に見えてきて別のシステムと繋ぎ合わせることで補うということが多くあります. これらのシステムでも実行時の情報が必要になることもあり, MLflowをメタデータの管理として扱うのであれば連携するシステムで必要な情報もMLflowに保存したいと思うのは自然な流れです.
実際に導入するには追加で保存したい情報を整理しチームや組織の間でそれらに対応するタグを決めて mlflow.set_tag で保存する方法が考えられます. しかし人間は間違えるものなのでコードの中で一つ一つ指定するのではなく自動的に情報を記録する仕組みを作るべきです.
このような場合にMLflow Pluginが有効です.
MLflow Plugin
MLflowにはpluginの仕組みがあります.
仕組みは単純でPythonのEntrypointパッケージを使い特定のエントリーポイントを持つPythonパッケージをロードしてMLflowのpluginの抽象クラスを継承したクラスの特定のメソッドを実行すること実現されています.
pluginの抽象化クラスは用途ごとに分けられています. MLflowの実験管理で特定の情報を自動的に保存するには mlflow.run_context_provider をエントリーポイントとするPythonパッケージで mlflow.tracking.context.abstract_context.RunContextProviderを継承したクラスを実装します.
RunContextProviderクラスは二つのメソッドを持ちます.
- def in_context(self):
- Boolを返す. Trueを返すとmlflowのクライアントが
tagsメソッドを実行しFalseを返すと何もしない. - 特定の状況下ではpluginの処理を実行したくない場合に使う.
- Boolを返す. Trueを返すとmlflowのクライアントが
- def tags(self):
- MLflowに記録させたいtagをDictで返す.
pluginのexampleとしてmlflowのクライアントのバージョンを client.version タグに記録する mlflow-plugin-example プラグインを用意しました. (kuromt/mlflow-plugin-example)
実装はシンプルです.
from mlflow.tracking.context.abstract_context import RunContextProvider import mlflow class LoggingExample(RunContextProvider): def in_context(self): return True def tags(self): return { 'client.version': mlflow.__version__ }
このpluginを実装するときは二つ注意があります.
一つ目は独自に定義するタグの名前付けです. MLflowのタグには利用者が任意に指定するタグとMLflowが内部で予約しているシステムタグがあるのですがpluginはMLflowのシステムタグも上書きできてしまうので意図的に上書きしたくない場合はタグの名付けに注意してください.
二つ目はRunContextProviderを継承したpluginの処理が実行されるタイミングです. このpluginは mlflow.start_run() を実行するタイミングで処理されます. そのため自動的に保存できるのは mlflow.start_run() を実行する前までに確定した情報のみです.
import mlflow # ここまでの処理内容と環境情報は自動的に保存できる with mlflow_start_run(): # ここの処理は自動保存できない
実際に実行してみる
MLflowとpluginの動作確認のためにJupyterhubとMLflow+MySQLの環境をDockerコンテナで構築するためのdocker-composeを含むデモ用のリポジトリを用意しました.
まずはデモ用のリポジトリからcloneして事前準備をします.
$ git clone https://github.com/kuromt/mlops_advent_calendar2020_demo.git $ cd mlops_advent_calendar2020_demo/docker-compose/
移動したディレクトリにMySQLのパスワードを記述したファイルを作ります.
$ cat << EOF > .env > MYSQL_ROOT_PASSWORD="mlflow" > MYSQL_DATABASE="mlflow" > MYSQL_USER="mlflow" > MYSQL_PASSWORD="mlflow" > EOF
続いてJupyterhubとMLflow + MySQLのコンテナを立ち上げます. 初めて立ち上げるときは自動でイメージのビルドが走ります.
$ docker-compose up -d
コンテナが立ち上がるとlocalhostの80ポートでMLflowに, 8080ポートでJupyterhubにアクセスできるようになります.
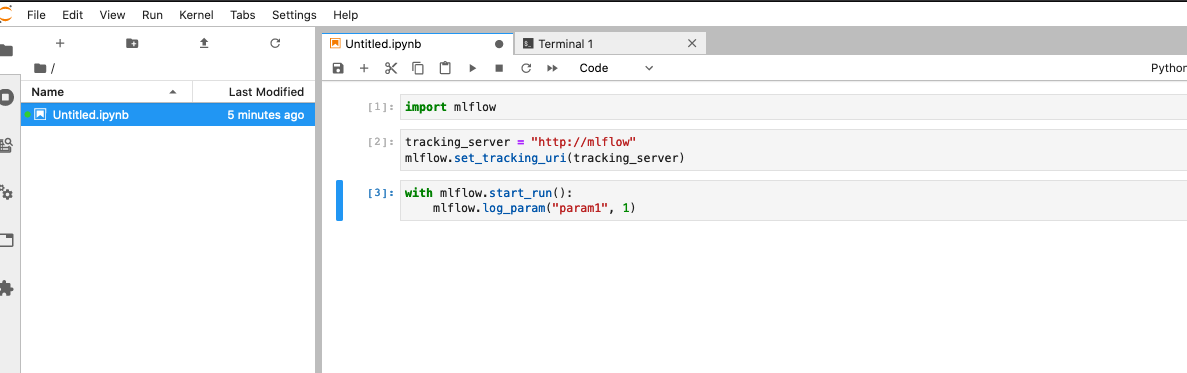
まずはpluginなしで実行してみます. JupyterのNotebookで以下を実行します.
import mlflow
tracking_server = "http://mlflow"
mlflow.set_tracking_uri(tracking_server)
with mlflow.start_run():
mlflow.log_param("param1", 1)
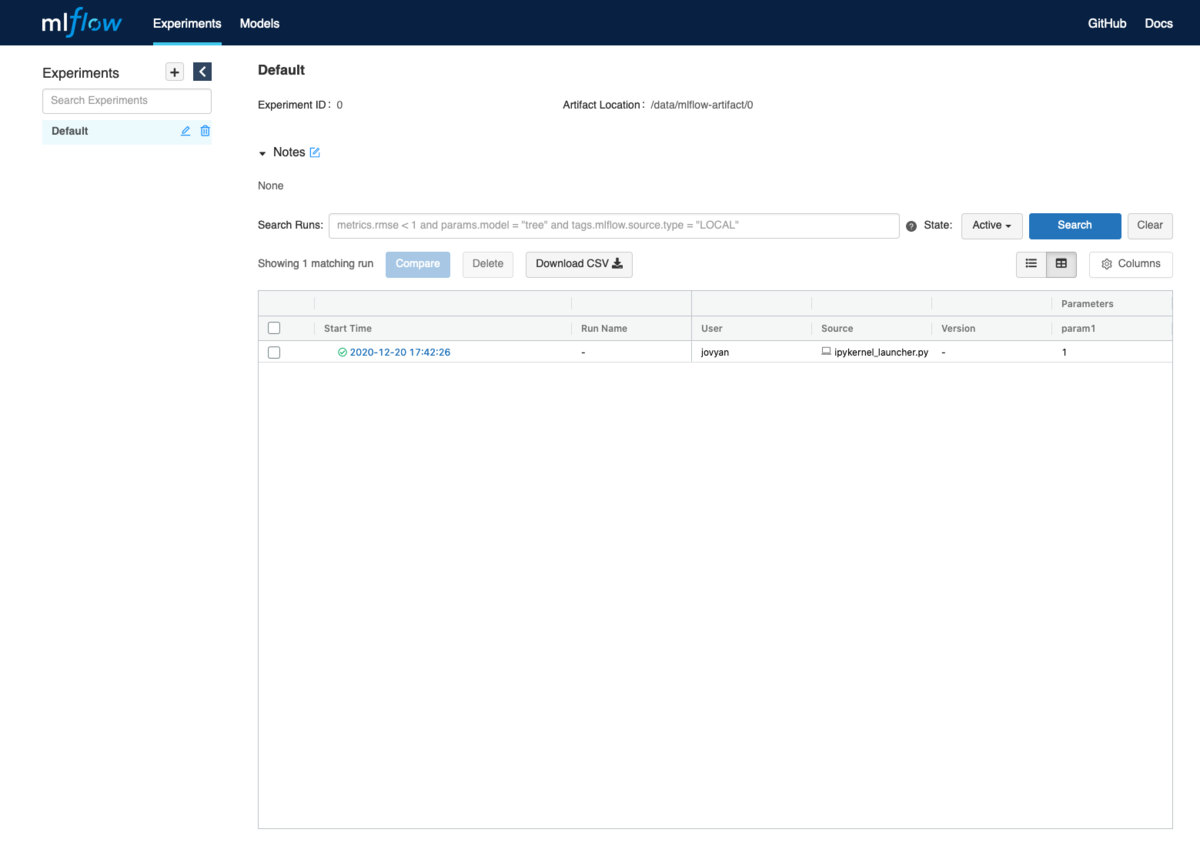
MLflowのUIにアクセスすると "default" の Experimentsにrunが追加されています.
次にJupyterhubの環境に先ほどのpluginをインストールします.
$ pip install git+https://github.com/kuromt/mlflow-plugin-example
インストールが終わればあとは自動的にmlflowのクライアントのバージョン情報を保存するpluginが有効になります. pluginの動作を確認するために先ほどのNotebookを再実行してみましょう. MLflowのpluginは import mlflow のタイミングで登録されるので先ほどの実行で使ったカーネルをrestartが必要です.
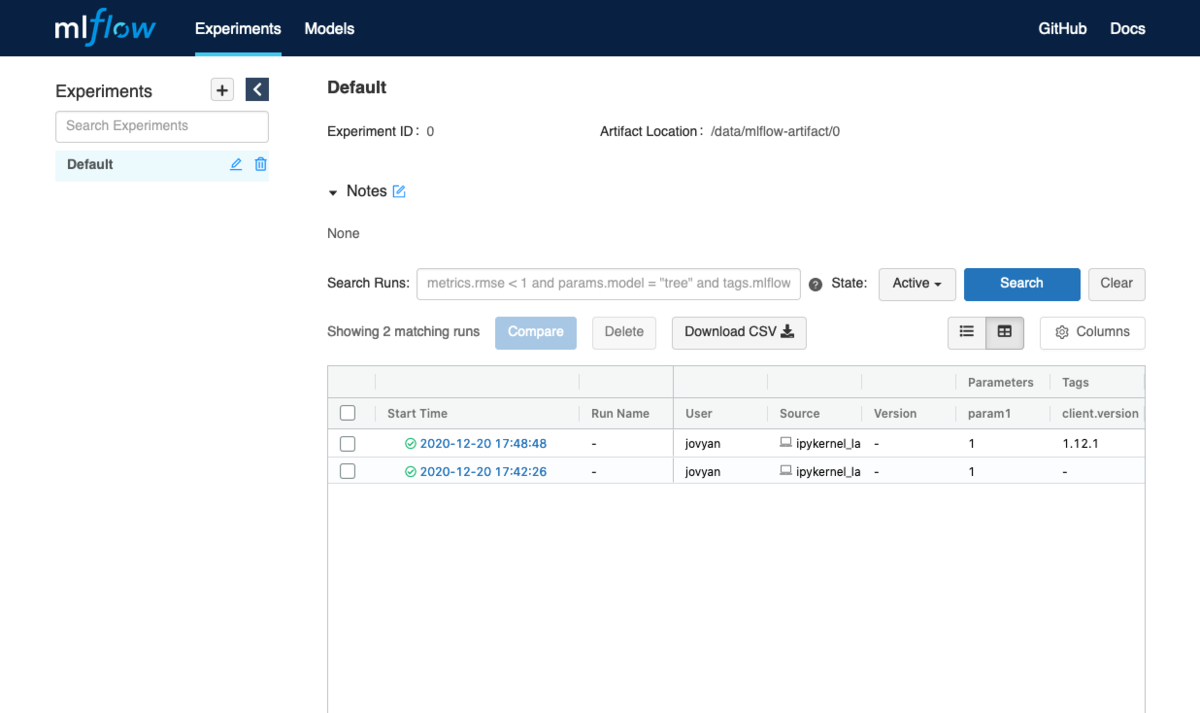
カーネルをrestartした後に先ほどと同じコードを実行しました.
MLflowのUIを確認してみると先ほど登録されていなかった client.version タグが記録されており, 自動的に実行時の情報が記録されていることが分かります.
このようにMLflow Pluginを使うことで独自に決めた実行情報のメタデータの保存を自動化できるようになります.
また, 保存したい情報が増えても実験用のコードを修正するのではなくpluginの機能を拡張するだけで済むので拡張性も高くなるというメリットもあります.
まとめ
この記事ではMLflowの実験管理を拡張するpluginの実装方法を紹介しました.
他のpluginを作りたい場合は Writing Your Own MLflow Plugins を参考にしながら実装してください.